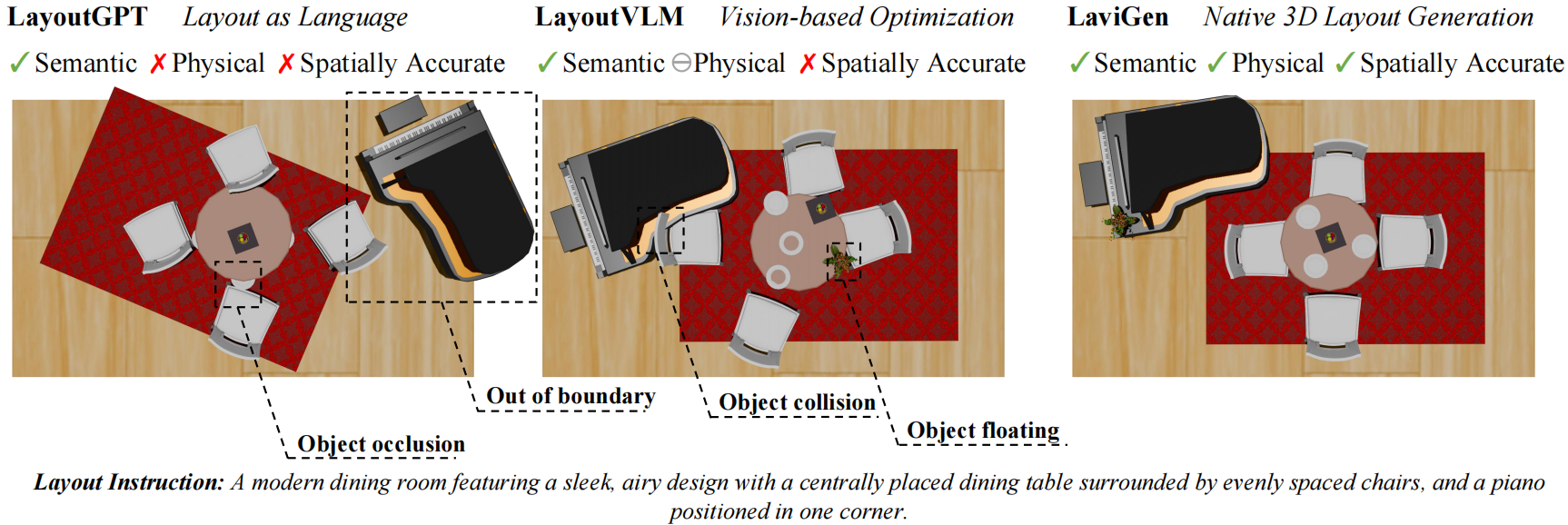
Click on furniture items on the right to add them to the scene one by one. Click again to remove.
Click on a scene card to open the interactive 3D viewer. You can rotate, pan, and zoom the generated 3D layout using mouse or touch controls.
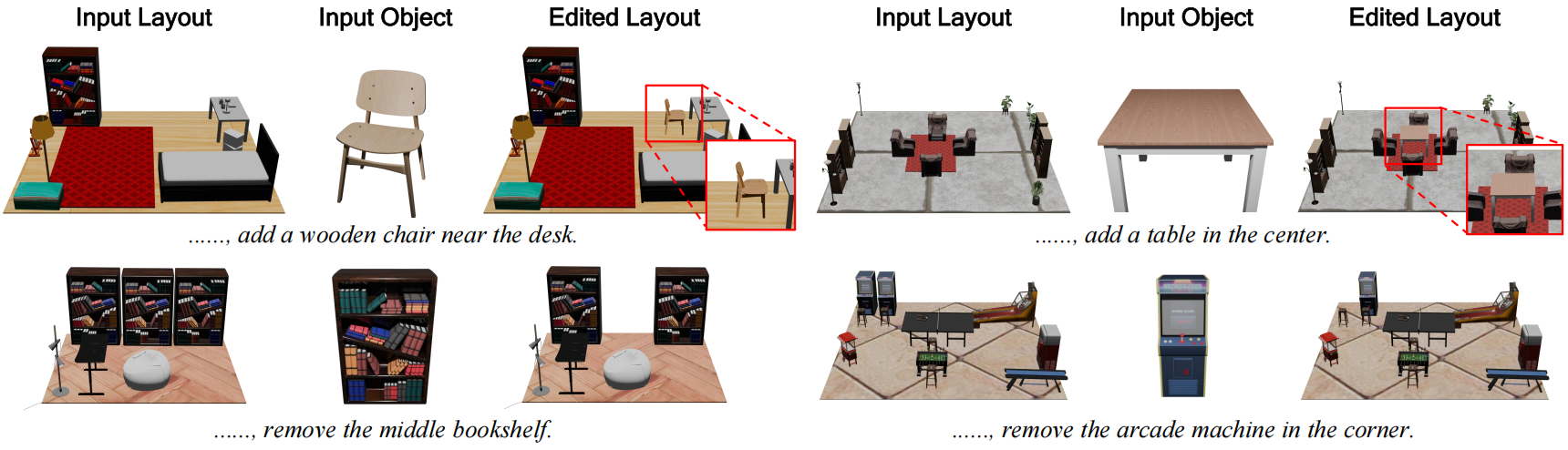
LaviGen naturally supports layout editing via a minimal autoregressive reformulation by swapping the prediction targets to enable context-aware regeneration. This enables object-level editing in native 3D space and produces spatially coherent edits.
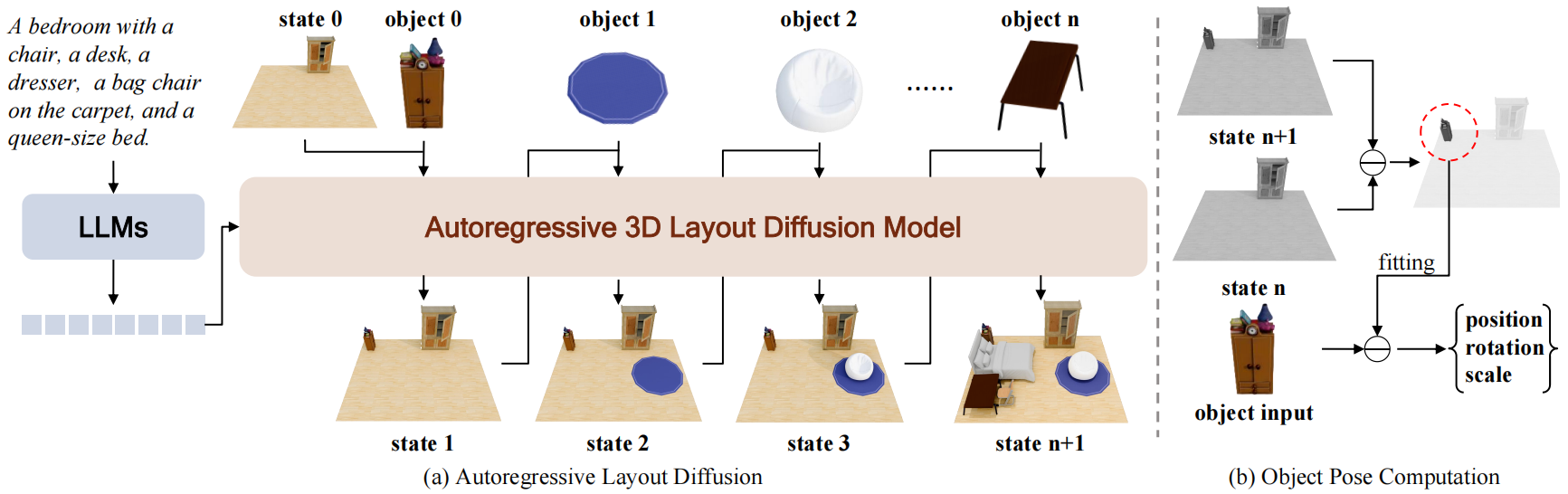
As shown in the figure above, LaviGen formulates 3D layout generation as an autoregressive process. Conditioned on LLM-encoded instructions, at step i it takes the current scene state Si and the target object Oi, and predicts the updated state Si+1. To recover the object pose, we localize the newly generated region by computing the spatial difference between Si+1 and Si, and then fit Oi to obtain its translation, rotation, and scale.
Concretely, at each step we encode the scene and the target object into latents, concatenate them with a noisy latent, and denoise the unified sequence with an adapted 3D layout diffusion model under instruction conditioning. We further introduce an identity-aware positional embedding that augments RoPE with latent-source identity, explicitly separating scene context from the newly inserted object while preserving spatial alignment. Finally, we apply dual-guidance self-rollout distillation to reduce exposure bias and accelerate inference, combining holistic scene-level supervision with step-wise object-aware guidance to obtain a robust few-step student for long-horizon generation.
If you find our work useful, please consider citing:
@misc{feng2026repurposing3dgenerativemodel, title={Repurposing 3D Generative Model for Autoregressive Layout Generation}, author={Haoran Feng and Yifan Niu and Zehuan Huang and Yang-Tian Sun and Chunchao Guo and Yuxin Peng and Lu Sheng}, year={2026}, eprint={2604.16299}, archivePrefix={arXiv}, primaryClass={cs.CV}, url={https://arxiv.org/abs/2604.16299}, }